

Van niet alle data in AFAS Profit wordt de historie opgeslagen, in andere gevallen kan je deze minder gemakkelijk ophalen via connectoren. Een voorbeeld is bijvoorbeeld de forecast module, je kan de huidige status ophalen, maar het is niet te zien welke statussen deze nog meer gehad heeft in het verleden. We gaan dus kijken naar Historische AFAS Data in Power BI.
Mocht je dergelijke data nu wel in Power BI beschikbaar willen hebben zijn er een aantal mogelijke oplossingen. In dit bericht gaan we in op de quick and dirty oplossing. Mocht ik later nog tijd vinden voor een zal ik het bericht verder uitbreiden.
Wat gaan we doen?
We gaan een export ophalen uit AFAS Profit middels een getconnector, deze slaan we vervolgens op in Azure Storage. Dat doen we volgens de instructies uit dit artikel, met een kleine aanpassing. De files worden voorzien van een datumveld, in dit voorbeeld neem ik nog niet het opschonen van de historie mee en bouwen we de historie in principe eindeloos op.
Aanpassing Powershell script
Het enige echte verschil met het script uit het eerder genoemde artikel zit in de loop waar we data ophalen. In het eerste geval overschrijven we altijd de vorige export, maar in dit geval willen we graag meer versies van het bestand opslaan, hiervoor hebben we dus een extra variabele nodig:
foreach ($conn in $todo.getConnectors.id) { $naamDatum = Get-Date -Format "dd-MM-yyyy" $url = 'https://**URL_VAN_PROFIT_OMGEVING**/profitrestservices/connectors/' + $conn + '?skip=-1&take=-1' $file = '.\' + $conn + '.json' Invoke-WebRequest -Uri $url -OutFile $file -Headers $Headers -UseBasicParsing $filename = $conn + '_' + $naamDatum '.json' Set-azurestorageblobcontent -File $file -container $ContainerName -Blob $filename -Context $Context -Force}Iedere keer dat het script nu draait zal er een export gemaakt worden van de getconnector, deze wordt vervolgens op de blobstorage opgeslagen met de datum in de filename. Het gevolg hiervan is wel dat je maar 1 export per dag kan maken, iedere keer dat je het script opnieuw draait wordt de huidige dag overschreven.
Power BI
De handigheid zit hem in het consolideren van de diverse bestanden in Power BI. Hiervoor moet je eenmalig wat stappen doorlopen, maar vervolgens zal iedere keer dat je de rapportage ververst de nieuwe data opgehaald worden als die aanwezig is.
Stap 1: Toevoegen blob storage als datasource
In dit artikel staat (onder andere) uitgelegd hoe je blob storage kan toevoegen als datasource in PowerBI. In dit geval kan je de eerste stappen daarvan herhalen tot je dit scherm ziet:
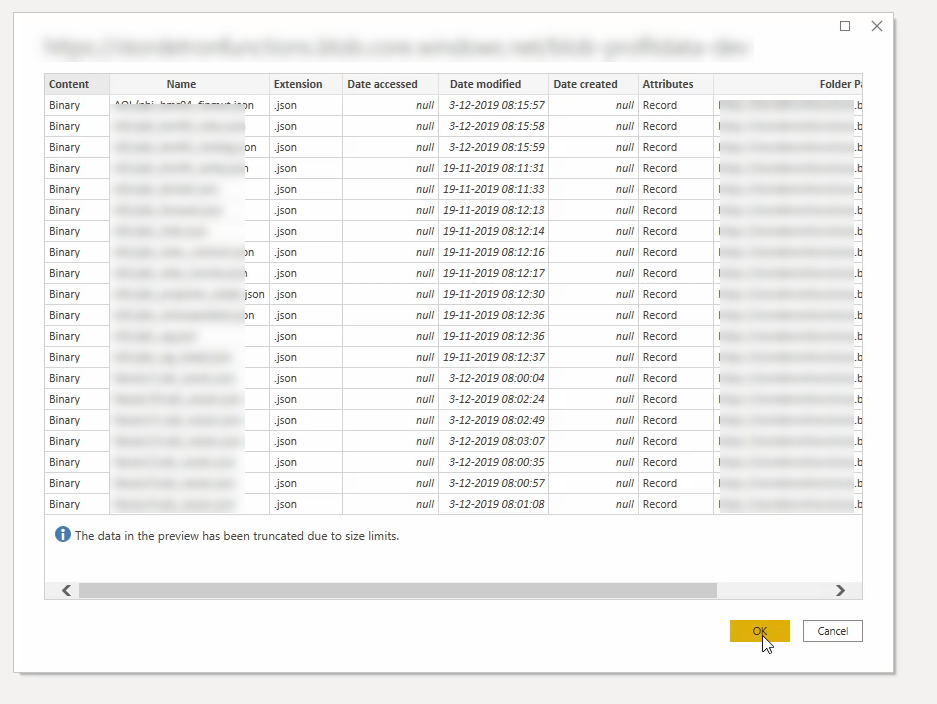
Klik hier op OK, er zal een query ingeladen worden waarmee we verder kunnen werken.
Stap 2: Filter de bestanden die je nodig hebt (indien nodig)
Je kan in de tabelweergave die je vervolgens te zien krijgt op het “Name” veld filteren zodat alleen de velden (bestandsnamen) overblijven die je nodig hebt. Je kan hier allerlei filters, waaronder tekstfilters gebruiken.
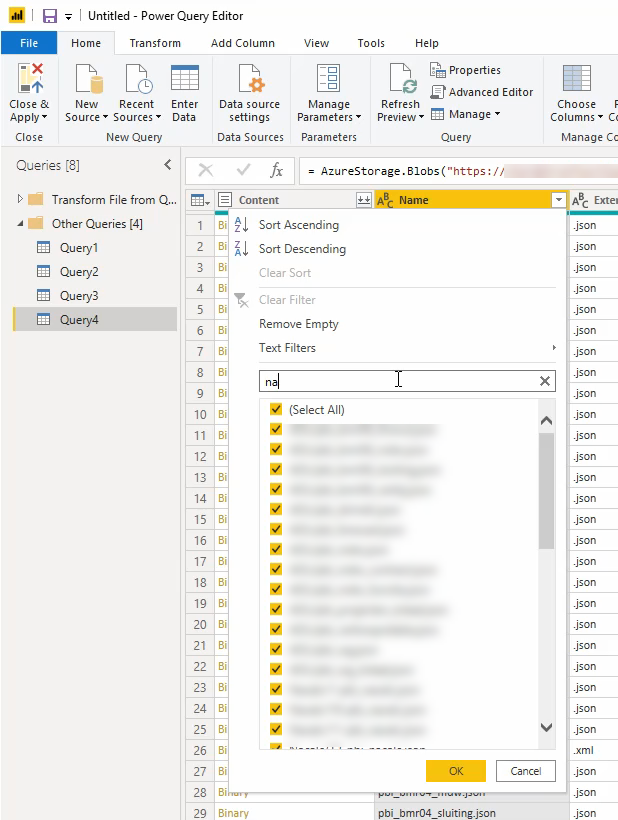
Het resultaat is dan als het goed is de lijst met json files die je wil inlezen. Dit filter wordt iedere keer bij het verversen van de data toegepast, dus als er na een verversing meer bronbestanden zijn die aan het filter voldoen worden deze ook mee ingelezen.
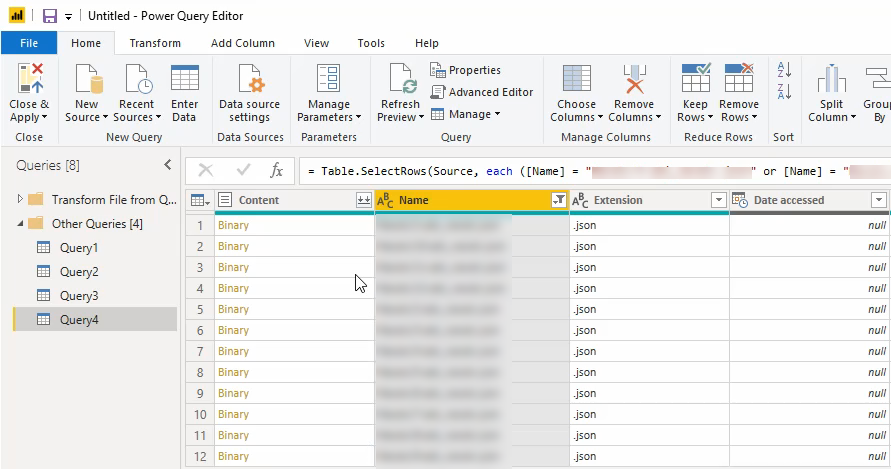
Stap 3: Het samenvoegen van de verschillende files
als het goed is hebben de files allemaal dezelfde structuur (LET OP: Dus niet de get-connector nog aanpassen nadat je dit gedaan hebt, dat levert problemen op met je historische data)! Je kan deze nu samenvoegen zodat we vanuit daar verder kunnen werken.
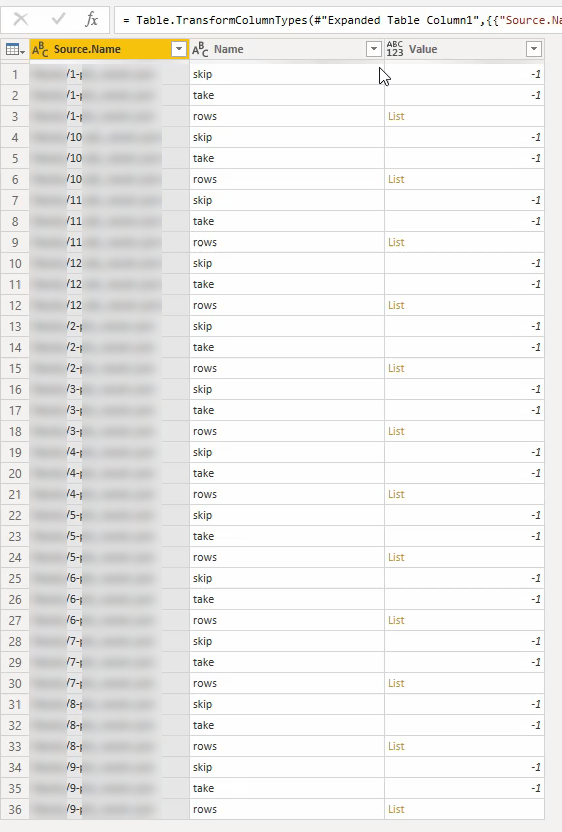
Klik voor het samenvoegen op de twee pijlen naar beneden naast “Content”

Je zal nu afhankelijk van de hoeveelheid data heel even moeten wachten, maar uiteindelijk zie je de volgende tabel (iets van die strekking)
Hier gaan we net als eerder weer een filter op toepassen, in de kolom “Name” filteren we zodat alleen de rows over blijven.
Stap 4: Bronbestanden “uitvouwen”
De volgende stap is het “uitvouwen” van het bronbestand. Door de aard van de JSON files moeten we de “lists” omzetten naar daadwerkelijke regels. Dat doen we als volgt:
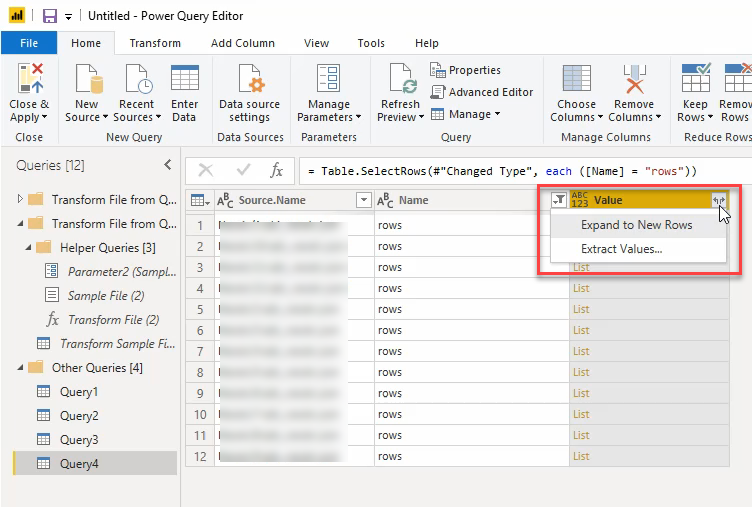
Door op de “expand” knop te klikken krijgen we een keuze, kies hier voor “Expand to New Rows”. Je zal wederom even moeten wachten, maar daarna zie je dat er voor iedere regel uit iedere JSON file een regel gemaakt is in de tabel:
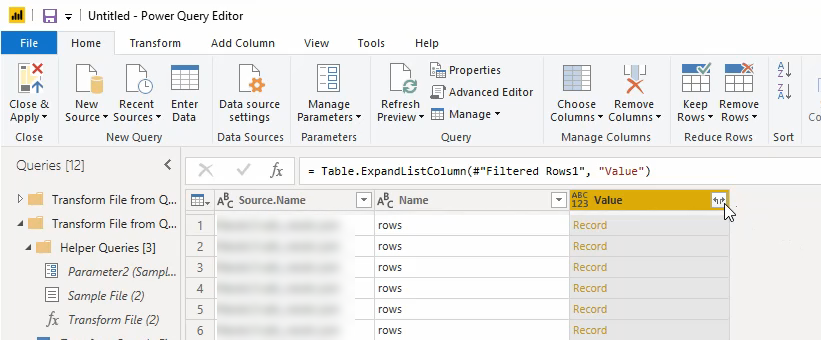
De vervolgstap is om te bepalen welke kolommen uit de bronbestanden we zichtbaar willen maken in de eindtabel:
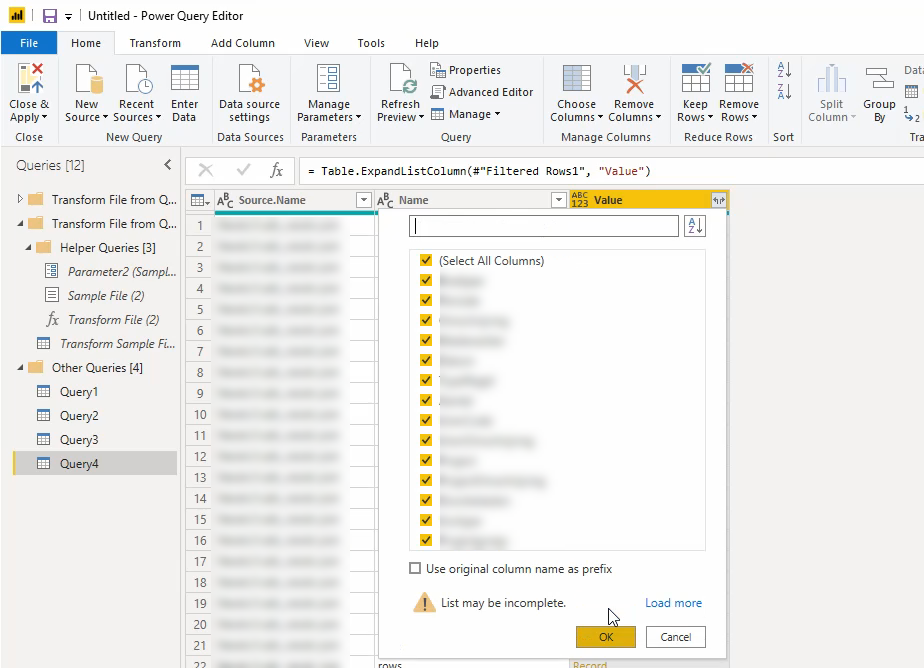
Vink de kolommen aan die je wil behouden en druk op OK.
Stap 5: Historisch datumveld prepareren
Je hebt nu de tabel met alle data, maar nog geen mogelijk om hier historisch op te filteren. Hiervoor moeten we het veld met de filename nog afmaken. we hebben de filename eerder in het Powershell script voorzien van de datum waarop de export gemaakt is. We zullen nu dus de overbodige tekst uit dat veld moeten weghalen en er een datumveld van moeten maken.
Onder het kopje “Transform” kan je voor “Replace” kiezen (selecteer eerst de kolom met de filenames):
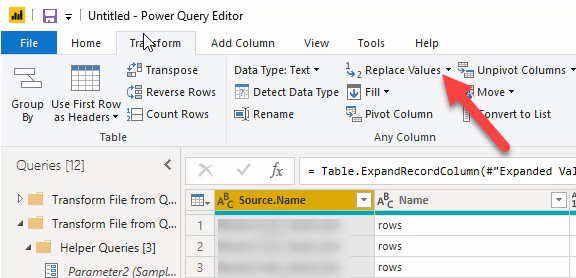
Je krijgt een dialoog te zien, afhankelijk van de opmaak kan je hier de tekst invullen die je niet meer nodig hebt. In mijn geval moet ik zowel voor als na de waarde die ik wil houden tekst verwijderen, dus ik moet deze handeling twee keer doen. Je voert de tekst in die je wil vervangen door “” oftewel niets, wat effectief betekend dat je de waarde verwijderd.
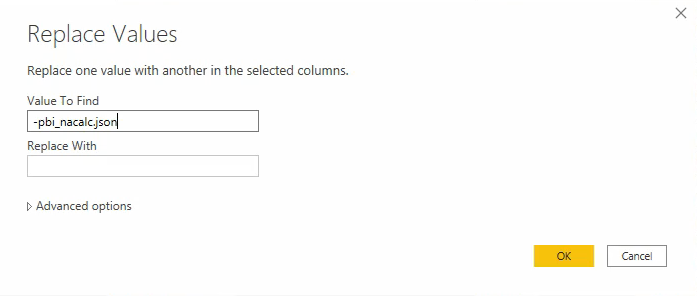
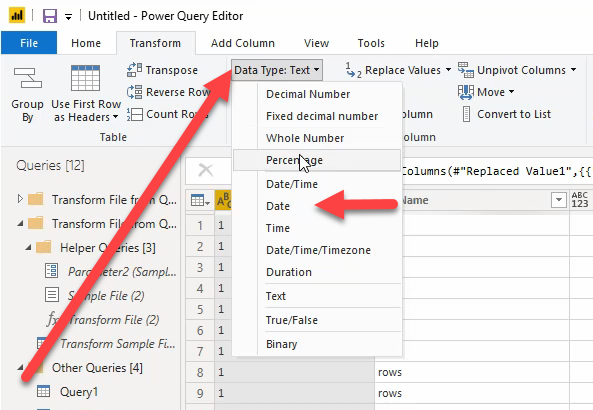
Wanneer je dit zo veel gedaan hebt als je nodig hebt om alleen de datum nog in het veld over te houden kan je het veld transformeren naar een datumveld:
Tot slot kan je eventueel nog Kolommen verwijderen die je niet nodig hebt of andere transformaties doorvoeren. Wanneer je klaar bent kie je voor Close & Apply en daarna kan je met je data aan de slag!
Doordat we nu de exportdatum per regel beschikbaar hebben kan je deze datum als peildatum gebruiken voor bijvoorbeeld historische forecast statussen of debiteurenstanden vanuit AFAS Profit.